
Weet jij wat de juiste selector is om te gebruiken bij web scraping? Web scraping is de laatste tien jaar erg populair geworden om gegevens van het internet te halen. Het helpt bedrijven gegevens te verzamelen en te analyseren om betere zakelijke beslissingen te nemen. Dankzij geautomatiseerde technologieën is web scraping nog nooit zo eenvoudig geweest als nu.
Ongeacht de tool of het framework dat je kiest, moet je echter een cruciale beslissing nemen om ervoor te zorgen dat je scraper de gegevens netjes schraapt. Dat is of je webelementen wilt extraheren met XPath of CSS selectors, wat je in dit artikel zult leren.
Laten we er eens induiken met een paar bestaande voorbeelden.
XPath staat voor XML Path Language. Het gebruikt echter een niet-XML syntaxis om tags of groepen tags uit een XML-document of HTML te selecteren, zoals bij web scraping. Met XPath kun je expressies schrijven om direct toegang te krijgen tot een HTML- of XML-element zonder de hele HTML-boom te doorlopen.
Om te begrijpen hoe je een element kunt benaderen met XPath, gaan we dieper in op een HTML-code. Ik ga ervan uit dat je de basis van HTML al kent.
<!doctype html>
<html xmlns=”http://www.w3.org/1999/xhtml” lang="en" xml:lang="en">
<head>
<meta charset="utf-8">
<title>Awesome Products at your Fingertips</title>
</head>
<body>
<h1>Description of product features</h1>
<p>These products are great. So let's just look at the features !</p>
<ul id="product-list" class=”basic-list”>
<li>Item 1</li>
<li>Item 2</li>
<li>Item 3</li>
</ul>
</body>
</html>
Je kunt de bovenstaande code in een editor naar keuze typen en opslaan als products.html. Vervolgens kun je het bekijken in een browser (bij voorkeur Google Chrome, omdat we daar dit voorbeeld mee zullen doorlopen).
Wanneer de browser deze code uitvoert, wordt de HTML gefraseerd en wordt er een boomstructuur van de elementen gemaakt. Dit staat bekend als het DOM (Document Object Model) in de volgende vorm:

Je kunt meer lezen over het DOM op de gegeven link. Nu richten we ons hier op het XPath over hoe je meteen naar elk van deze elementen kunt navigeren zonder de hele boom te doorlopen. Laten we dus beginnen met de basisterminologie van het Xpath.
Met XPath is het meest fundamentele element een knooppunt. Knooppunten zijn gewoon de individuele elementen die je net zag in de DOM-boom. Naarmate we verder gaan in dit artikel, zul je nog ontdekken dat knooppunten bestaan uit tag-elementen, attributen, strings die er waarden aan toekennen, enzovoort. Er zijn er zeven in elke XML- of HTML-pagina en laten we elk type knooppunt eens nader bekijken.
Hoewel de bovenstaande drie de belangrijkste zijn, is het voor de informatie ook belangrijk om de volgende vier te kennen.
Er zijn twee manieren om dit te doen. Ten eerste, laten we het demonstreren of een voorbeeld coderen. Zoals ik hierboven al zei, hoop ik dat je het op je lokale schijf hebt opgeslagen en klaar bent om het in je browser te bekijken.
Beweeg de muis over item 1 wanneer de pagina wordt geladen en klik er met de rechtermuisknop op. Selecteer vervolgens Inspecteren uit de menu-items die verschijnen, zoals weergegeven in de onderstaande schermafbeelding:

Then you would be able to find the full XPath by clicking on the <li> element in the console and selecting “copy” from the drop-down menu, and then specifying “Copy full XPath as shown below:
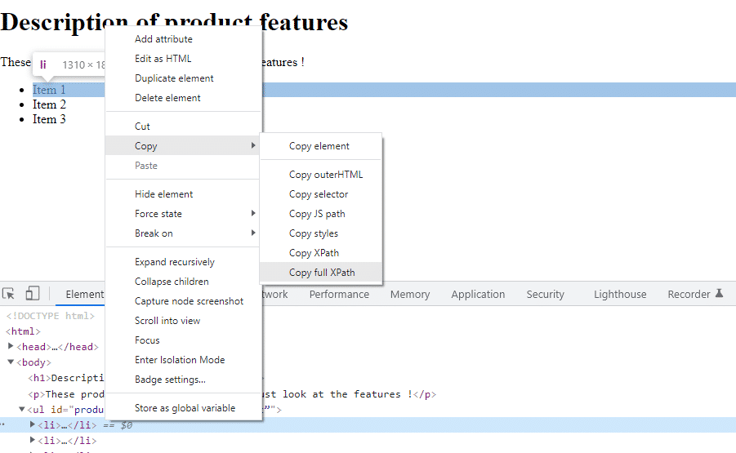
Nadat je het in een tekstbestand of ergens anders hebt geplakt, zou je het volgende krijgen:
/html/body/ul/li[1]Dit staat bekend als het absolute pad. Ik zal hieronder uitleggen hoe je het hebt afgeleid.
Stap 1 => li[1] /Hier staat één voor het eerste li element
Stap 2 => /li[1]
Stap 3 => ul/li[1]
Stap 4 => /ul/li[1]
Stap 5 => body/ul/li[1]
Stap 6 => /body/ul/li[1]
Stap 7 => html/body/ul/li[1]
Stap 8 => /html/body/ul/li[1]
With this method, you need to work your way backward, starting from the target element all the way back to the root element. You add a forward slash before the element you have just added as you write each element. So let’s look at how you could work out the XPath for the first <li> element manually:
Hoewel de bovenstaande methode lang lijkt, zal het je helpen begrijpen hoe je het volledige XPath opbouwt. Nu over naar de relatieve methode.
//*[@id="product-list"]/li[1]As you can see, it is pretty short, and the path is relative to the parent <ul> element. Since the <li> element does not have an id attribute, its relative path is relative to the <ul> element.
De significante verschillen zijn dat volledig XPath niet leesbaar en moeilijk te onderhouden is. De andere voor de hand liggende zorg is dat als er wijzigingen zijn aan een element vanaf het root element, het absolute XPath niet geldig zal zijn. Het is dus zinvol om het relatieve XPath te gebruiken.
Maar laten we, voordat we daar verder op ingaan, eerst de voor- en nadelen bekijken.
Met XPath hoef je je geen zorgen te maken als je de naam van een element niet weet, omdat je de functie contains kunt gebruiken om te zoeken naar waarschijnlijke overeenkomsten. Daarom kun je hoger in de DOM zoeken naar items om te scrapen.
Een ander belangrijk voordeel van CSS is dat het werkt in oudere legacy browsers, zoals verouderde versies van Internet Explorer.
Zoals je hierboven hebt geleerd, is het belangrijkste nadeel dat het gemakkelijker te breken is wanneer je de elementen in het pad wijzigt. Het kan moeilijk te begrijpen zijn in vergelijking met de CSS selectors die je hieronder zult ontdekken.
Bij het ophalen van elementen uit het XPath is de prestatie ook veel langzamer dan die van CSS.
Zoals je al weet, staat CSS voor Cascading Style Sheets die prominent worden gebruikt bij het stylen van HTML-elementen op een webpagina. Deze stijlen omvatten het toepassen van kleuren op je lettertype, achtergrondafbeeldingen en kleuren, het uitlijnen en positioneren van elementen en het vergroten/verkleinen van spaties tussen alinea's.
Om een stijl in te stellen op een HTML-element, moet je die specificeren via een CSS Selector. Laten we beginnen met een eenvoudig voorbeeld met de opmaak in de volgende sectie.
<h1 id="main-heading" class="header-styles" name="h1name">What are CSS Selectors?</h1>Dus hier is de CSS selector voor het bovenstaande element:
Je kunt ze ook combineren:
h1.header-styles-DezeCSS-selector selecteert h1-elementen met klasse header-styles.
De operator > wordt gebruikt om kinderen te selecteren. De operator + daarentegen kiest de eerste broer of zus en de operator ~ wordt gebruikt om alle broers of zussen te selecteren. Enkele voorbeelden:
In tegenstelling tot XPath, dat de Beautiful Soup niet ondersteunt, worden CSS selectors ondersteund door de meest effectieve scraping bibliotheken. In tegenstelling tot XPath zijn CSS-selectors ook eenvoudiger te leren en te onderhouden. Bijna alle browsers ondersteunen het, behalve oudere browsers onder Internet Explorer versie 8. Deze browsers worden tegenwoordig echter zelden gebruikt.
Zelfs als je de oudere versies van Internet Explorer buiten beschouwing laat, kunnen er nog steeds inconsistenties zijn in hoe ze worden weergegeven op verschillende browsers.
Omdat er verschillende CSS-versies zijn, kunnen deze verwarring veroorzaken bij zowel ontwikkelaars als beginners.
Een andere essentiële factor in de huidige webtechnologie is de beveiliging van CSS.

Het duidelijke verschil tussen XPath en CSS is dat XPath bidirectioneel is. Dit betekent dat je in beide richtingen in de DOM-boom kunt navigeren. Met CSS kun je echter alleen van de parent node naar child nodes gaan, wat bekend staat als eenrichtingsverkeer.
Zoals besproken in de vorige secties, is XPath moeilijker te onderhouden en geen goede kandidaat voor effectieve leesbaarheid. Aan de andere kant, hoewel XPath kan werken in oudere browsers, verschilt de manier waarop het wordt weergegeven van browser tot browser.
Daarom heeft de CSS in dat opzicht een streepje voor.
XPATH valt op omdat CSS alleen van de ouders naar het kind kon gaan in specifieke gebieden zoals het omhoog gaan in de DOM-boom. Wat betreft snelheid heeft CSS een streepje voor.
Het snelheidsverschil tussen XPath en CSS telt echter niet veel als het op web scraping aankomt. Er zijn andere factoren om rekening mee te houden, zoals netwerklatentie bij web scraping.
CSS zou je eerste keuze zijn als het gaat om Beautiful Soup, omdat het XPath niet ondersteunt.
Er is geen precies antwoord op de vraag welke selectors je moet gebruiken voor je web scraping-project. Zoals je in dit artikel hebt ontdekt, heeft XPath in bepaalde situaties een streepje voor, terwijl CSS er in andere situaties uitspringt.
Daarom moet je rekening houden met specifieke vitale punten zoals traverseren, browserondersteuning en enkele van de technische mogelijkheden die we hebben besproken. We hopen dat je in de praktijk zult brengen wat je hebt geleerd en dat je op de hoogte blijft van meer artikelen.