
According to Statista, in 2021, retail eCommerce sales amounted to 4.9 trillion US dollars worldwide. That is a lot of money, and it is predicted that by 2025, it will reach the 7 trillion US dollars mark. As you can guess, with this great revenue potential in e-commerce, the competition is bound to be aggressive.
Volgens Statista bedroeg de omzet van eCommerce in 2021 wereldwijd 4,9 biljoen dollar. Dat is veel geld en er wordt voorspeld dat dit in 2025 zal zijn opgelopen tot 7 biljoen US dollar. Je kunt wel raden dat met dit grote inkomstenpotentieel in e-commerce, de concurrentie agressief zal zijn.
Daarom is het noodzakelijk om je aan te passen aan de laatste trends om te overleven en te gedijen in deze ultracompetitieve atmosfeer. Als je een marktspeler bent, is de eerste stap in deze richting het analyseren van je concurrenten. Een belangrijk onderdeel van deze analyse is de prijs. Door de prijzen van producten bij concurrenten te vergelijken, kun je de meest concurrerende prijs in de markt aanbieden.
Als eindgebruiker kun je ook de laagste prijzen voor elk product ontdekken. Maar de echte uitdaging hier is dat er veel e-commerce websites online beschikbaar zijn. Het is onmogelijk om handmatig naar elke website te gaan en de prijs van elk product te controleren. Dit is waar computercodering om de hoek komt kijken. Met behulp van Python-code kunnen we informatie van de websites halen. Hierdoor wordt het schrapen van prijzen van websites een fluitje van een cent.
Dit artikel bespreekt hoe je prijzen van websites van een e-commerce website kunt scrapen met Python als voorbeeld.
Voel je vrij om het gedeelte te bekijken dat je het meest wilt weten.
Stap 1: De benodigde bibliotheken installeren:
Stap 2: Extractie van webgegevens:
Stap 4: De code lussen om meer gegevens te krijgen:
Voordat we ingaan op het schrapen van prijzen van websites, moeten we de definitie en wettelijke factoren achter web scraping bespreken.
Bij web scraping, ook bekend als web data extraction, worden bots gebruikt om door een website te crawlen en de nodige gegevens te verzamelen. Wanneer je de term "web scraping" hoort, is de eerste vraag die bij je opkomt of web scraping legaal is of niet.
Dit antwoord hangt af van een andere vraag: "Wat gaat u doen met de geschraapte gegevens?" Het is legaal om gegevens van andere websites te halen voor persoonlijke analyse, omdat alle weergegeven informatie voor openbare consumptie is. Maar als de gegevens die je gebruikt voor je eigen analyse op welke manier dan ook gevolgen hebben voor de oorspronkelijke eigenaar van de gegevens, is het illegaal. Maar in 2019 oordeelde een Amerikaanse federale rechtbank dat web scraping niet in strijd is met hackingwetten.
Kortom, het is altijd beter om te oefenen met het extraheren van gegevens van websites die geen invloed hebben op de oorspronkelijke eigenaar van de gegevens. Een ander ding om in gedachten te houden is om alleen te scrapen wat je nodig hebt. Het scrapen van tonnen gegevens van de website zal waarschijnlijk de bandbreedte of prestaties van de website beïnvloeden. Het is belangrijk om die factor in de gaten te houden.
Als je niet goed weet hoe je moet controleren of de website web scraping toestaat of niet, dan zijn er manieren om dat te doen:
Nu zou je een basiskennis moeten hebben van web scraping en de wettelijke factoren achter web scraping. Laten we eens kijken hoe we een eenvoudige webscraper kunnen bouwen om de prijzen van laptops van een e-commerce website te vinden. De taal Python wordt samen met het Jupyter-notitieblok gebruikt om de scraper te bouwen.
In Python verzamelt een bibliotheek genaamd "BeautifulSoup" gegevens van andere websites om prijzen van websites te schrapen.
Samen met BeautifulSoup gebruiken we "Pandas" en "requests". Pandas wordt gebruikt voor het maken van een dataframe en het uitvoeren van gegevensanalyse op hoog niveau, en request is de HTTP-bibliotheek die helpt bij het opvragen van gegevens van websites. Gebruik de volgende code in python om deze bibliotheken te installeren:
van bs4 importeer BeautifuSoup
importeer verzoeken
importeer pandas als pd
importeer urllib.parseIn dit voorbeeld wordt de naam van de website niet zichtbaar gemaakt. Als u de hierboven vermelde wettelijke richtlijnen voor web scraping en de volgende stappen volgt, krijgt u het resultaat. Zodra je het adres van de website hebt verkregen, kun je het opslaan in een variabele en controleren of het verzoek is geaccepteerd of niet. Volg voor het extraheren van gegevens de onderstaande pythoncode:
seed_url = 'example.com/laptops'.
response = requests.get(seed_url) #Controleren of het verzoek is geaccepteerd of niet
response.status_code #200 is de code die verwijst naar de status OK, wat betekent dat het verzoek is geaccepteerd
200De status_code geeft het resultaat, of we een verzoek hebben gekregen of niet. Hier betekent de status_code '200' dat het verzoek is geaccepteerd. Nu hebben we het verzoek gekregen. De volgende stap is het analyseren van de gegevens.
Parsering is het proces van het omzetten van een formaat naar een ander formaat. In dit geval wordt HTML-parsing uitgevoerd, waarbij de gegevens (HTML) worden geconverteerd naar een intern formaat (python) zodat de omgeving de gegevens kan uitvoeren. De volgende afbeelding toont de pythoncode om het proces van gegevens parsen uit te voeren met behulp van de BeautifulSoup-bibliotheek:
soep = BeautifulSoup(response.content, 'html.parser')Door de webpagina's te parsen, krijgt Python alle gegevens zoals namen, tags, prijzen, afbeeldingsdetails en details over de paginalay-out.
Zoals hierboven vermeld, is ons doel om de prijzen van de laptop op een e-commerce website te vinden. De benodigde informatie voor dit voorbeeld zijn de naam van de laptop en de prijs. Om die te vinden, bezoek je de webpagina die je wilt schrapen. Klik met de rechtermuisknop op de webpagina en selecteer de "inspect option". Je krijgt dan een terminal als deze te zien:
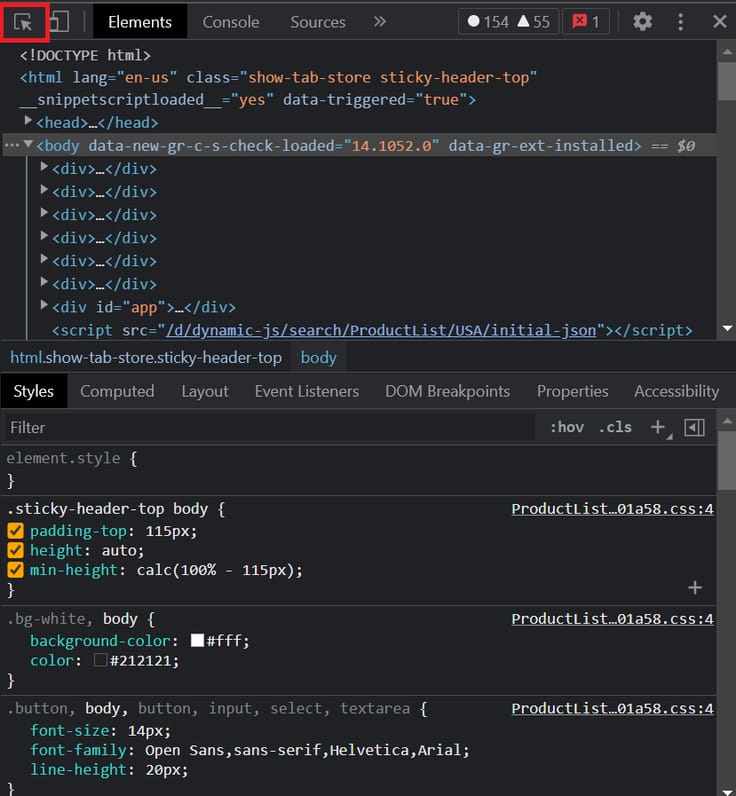
Gebruik de gemarkeerde optie om met de muis over de laptopnaam, prijs en container te gaan. Als je dat doet, zie je de div-code gemarkeerd in de terminal. Van daaruit kun je de details van de klasse opvragen. Zodra je de klassendetails hebt, voer je alle informatie in de onderstaande pythoncode in.
results = soup.find_all('div', {'class':'item-container'})
len(results)
results[1]
#NECESSARY DATA:
#Name and Price of the item
Name_of_the_Item= soup.find('a', {'class':'item-title'}).get_text()
print(Name_of_the_Item)
price=soup.find('li', {'class':'price-current'}).get_text()
print(price)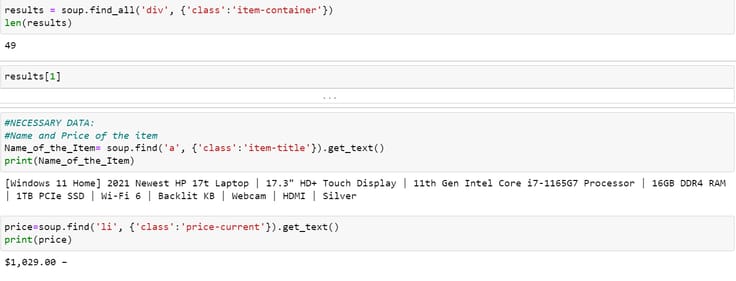
Nu heb je de prijs voor één laptop. Wat als je 10 laptops nodig hebt? Het is mogelijk door dezelfde code te gebruiken in een for-lus. Python-code voor het uitvoeren van een for-lus wordt hieronder weergegeven.
Name_of_the_item = []
Price_of_the_item = []
for soup in results:
try:
Name_of_the_item.append(soup.find('a', {'class':'item-title'}).get_text())
except:
Name_of_the_item.append('n/a')
try:
Price_of_the_item.append(soup.find('li', {'class':'price-current'}).get_text())
except:
Price_of_the_item.append('n/a')
print(Name_of_the_item)
print(Price_of_the_item)Nu we alle stappen voor web scraping hebben doorlopen, kunnen we kijken hoe de uitvoer eruitziet.


Dit is geen leesbaar formaat. Om dit om te zetten in een leesbaar formaat, bij voorkeur een tabelformaat (dataframe), kun je de pandas-bibliotheek gebruiken. Hieronder staat de pythoncode voor het uitvoeren van deze stap.
#Creating a dataframe
product_details=pd.DataFrame({'Name': Name_of_the_item, 'Price':Price_of_the_item})
product_details.head(10)
Nu ziet het er leesbaar uit. De laatste stap is het opslaan van dit dataframe in een CSV-bestand voor analyse. De pythoncode om het dataframe op te slaan in CSV-formaat staat hieronder.
product_details.to_csv("Web-scraping.csv")Hiermee kun je eenvoudige concurrentieanalyses uitvoeren, gericht op de prijzen van de producten. In plaats van het handmatig te doen, is geautomatiseerd web scraping met python een efficiënte manier die je veel tijd bespaart.
Zoals hierboven besproken over hoe je kunt controleren of de website web scraping toestaat, zal proxies je helpen het probleem op te lossen.
Proxies helpen je om je lokale IP-adres te maskeren en kunnen je online anoniem maken. Dit kan je helpen om zonder problemen gegevens van websites te schrapen. ProxyScrape is de beste plek om premium proxies en gratis proxies te krijgen. De voordelen van het gebruik van ProxyScrape zijn:
In dit artikel hebben we gezien hoe je prijzen van websites kunt schrapen met behulp van python. Web scraping is een efficiënte manier om gegevens online te krijgen. De meeste Kickstarters gebruiken web scraping om de nodige gegevens te verkrijgen door alle ethische richtlijnen te volgen zonder veel tijd en middelen te spenderen. Er zijn speciale web scraping tools online beschikbaar voor verschillende informatie, zoals prijzen en productinformatie. Je kunt hier terecht voor meer informatie over web scraping tools.
Dit artikel hoopt genoeg informatie te hebben gegeven om de vraag "hoe schrap ik prijzen van websites?" te beantwoorden. Maar de realiteit is dat er geen eenduidige manier is om prijzen van websites te schrapen. Je kunt speciale web scraping tools gebruiken om prijzen van websites te schrapen of je eigen python scripts maken om prijzen van websites te schrapen. In beide gevallen kun je tijd besparen en zonder problemen veel gegevens verzamelen.
DISCLAIMER: Dit artikel is uitsluitend bedoeld als leermiddel. Zonder de juiste richtlijnen te volgen, kan het uitvoeren van web scraping worden beschouwd als een illegale activiteit. Dit artikel ondersteunt geen illegale web scraping in welke vorm dan ook.