
Data Parsing is een term die je vaak tegenkomt als je met grote hoeveelheden gegevens werkt, vooral voor degenen die gegevens van het web schrapen en voor software engineers. Data parsing is echter een onderwerp waar dieper op ingegaan moet worden. Bijvoorbeeld, wat is data parsing precies en hoe implementeer je het in de echte wereld.
Dit artikel zal alle bovenstaande vragen beantwoorden en een overzicht geven van de belangrijkste terminologieën die te maken hebben met het parsen van gegevens.
Wanneer je grote hoeveelheden gegevens uit web scraping haalt, zijn ze in HTML-formaat. Helaas is dit geen leesbaar formaat voor niet-programmeurs. Dus moet je de gegevens verder bewerken om ze in een voor mensen leesbaar formaat te maken dat geschikt is voor analyse door datawetenschappers. Het is de parser die het meeste zware werk verricht bij het parsen.
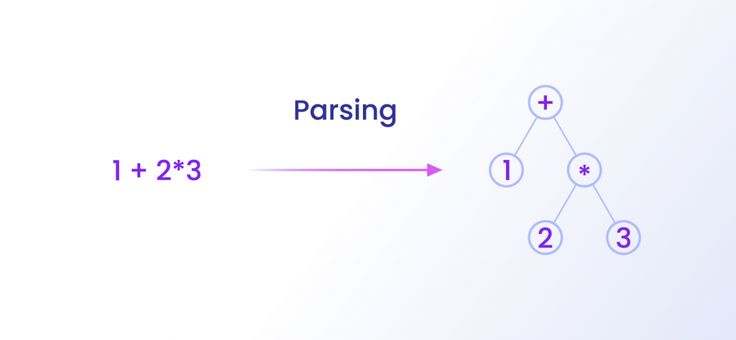
Een parser converteert gegevens in de ene indeling naar gegevens in een andere vorm. De parser converteert bijvoorbeeld de HTML-gegevens die je via scraping hebt verkregen naar JSON, CSV en zelfs een tabel, zodat ze in een formaat staan dat je kunt lezen en analyseren. Het is ook het vermelden waard dat de parser niet gebonden is aan een bepaald gegevensformaat.
De parser parseert niet elke HTML-string, omdat een goede parser de vereiste gegevens in HTML-tags onderscheidt van de rest.
Zoals vermeld in de vorige paragraaf is de parser van nature uitzonderlijk flexibel, omdat hij niet gebonden is aan één specifieke technologie. Daarom wordt hij door een grote verscheidenheid aan technologieën gebruikt:
Scripttalen- dit zijn talen die geen compiler nodig hebben om te worden uitgevoerd, omdat ze worden uitgevoerd op basis van een reeks commando's in een bestand. Typische voorbeelden zijn PHP, Python en JavaScript.
Java en andere programmeertalen- Hoog-niveau programmeertalen zoals Java gebruiken een compiler om de broncode om te zetten naar assembleertaal. De parser is een belangrijk onderdeel van deze compilers die een interne representatie van de broncode maakt.
HTML en XML- in het geval van HTML haalt de parser de tekst uit HTML-tags zoals titel, koppen, alinea's enz. Een XML-parser is een bibliotheek die het lezen en manipuleren van XML-documenten vergemakkelijkt.
SQL en databasetalen- De SQL-parser parseert bijvoorbeeld een SQL-query en genereert de velden die in de SQL-query zijn gedefinieerd.
Modelleringstalen - een parser in modelleringstalen stelt ontwikkelaars, analisten en belanghebbenden in staat om de structuur van het gemodelleerde systeem te begrijpen.
Interactieve gegevenstalen- worden gebruikt bij de interactieve verwerking van grote hoeveelheden gegevens, waaronder ruimtewetenschap en zonnefysica.
De belangrijkste reden voor de behoefte aan parsing is dat verschillende entiteiten gegevens in verschillende formaten nodig hebben. Parsering maakt het dus mogelijk om gegevens te transformeren zodat een mens of, in sommige gevallen, de software ze kan begrijpen. Een prominent voorbeeld van het laatste zijn computerprogramma's. Eerst schrijven mensen ze in een formaat dat ze kunnen begrijpen met een high-level taal analoog aan een natuurlijke taal zoals het Engels dat we dagelijks gebruiken. Daarna vertalen de computers ze in een vorm tot code op machineniveau die de computers begrijpen.
Parsing is ook nodig in situaties waar communicatie nodig is tussen twee verschillende software, bijvoorbeeld bij het serialiseren en deserialiseren van een klasse.
Tot nu toe ken je de fundamentele concepten van data parsing. Nu is het tijd om de belangrijke concepten van data parsing en de werking van de parser te verkennen.

Reguliere expressies zijn een reeks tekens die een bepaald patroon definiëren. Ze worden het meest gebruikt door high-level en scripttalen om een e-mailadres of geboortedatum te valideren. Hoewel ze ongeschikt worden geacht voor het parsen van gegevens, kunnen ze nog steeds worden gebruikt voor het parsen van eenvoudige invoer. Deze misvatting ontstaat omdat bepaalde programmeurs reguliere expressies gebruiken voor elke parsingtaak, zelfs wanneer ze niet gebruikt zouden moeten worden. In dergelijke omstandigheden is het resultaat een reeks reguliere expressies die aan elkaar zijn gehackt.
Je kunt reguliere expressies gebruiken om sommige eenvoudige programmeertalen te ontleden, ook wel reguliere talen genoemd. Dit geldt echter niet voor HTML, dat je kunt beschouwen als een eenvoudige taal. Dit komt doordat je binnen HTML-tags een willekeurig aantal willekeurige tags tegenkomt. Bovendien heeft HTML volgens zijn grammatica recursieve en geneste elementen die je niet kunt classificeren als gewone taal. Daarom kun je ze niet ontleden, hoe slim je ook bent.
Grammatica is een verzameling regels die een taal syntactisch beschrijft. De grammatica is dus alleen van toepassing op de syntaxis en niet op de semantiek van een taal. Met andere woorden, de grammatica is van toepassing op de structuur van een taal en niet op de betekenis ervan. Laten we het onderstaande voorbeeld eens bekijken:
HI: "HI".
NAAM: [a-zA-z] +
Begroeting: HI NAAM
Twee van de mogelijke uitgangen voor het bovenstaande stukje code kunnen "HI SARA" of "HI Codering" zijn. Wat betreft de structuur van de taal zijn ze allebei correct. In de tweede uitvoer is "Codering" echter semantisch onjuist, omdat het geen persoonsnaam is.
Anatomie van grammatica
We kunnen de anatomie van de grammatica bekijken met de veelgebruikte vormen, zoals de Backus-Naur Form (BNF). Deze vorm heeft varianten, zoals de Uitgebreide Backus-Naur Vorm, en geeft herhaling aan. Een andere variant van BNF is de Augmented Backus-Naur Form. Deze wordt gebruikt bij het beschrijven van bidirectionele communicatieprotocollen.
Wanneer je een typische regel in Backus-Naur vorm gebruikt, ziet deze er als volgt uit:
<symbol> : : _expression_
The <symbol> is nonterminal, which means you can replace it with elements on the right, _expression_. The _expression_ could contain terminal symbols as well as nonterminal symbols.
Nu vraag je je misschien af wat terminale symbolen zijn? Dat zijn symbolen die in geen enkel grammaticaonderdeel als symbool voorkomen. Een typisch voorbeeld van een eindsymbool is een tekenreeks zoals "Programma".
Omdat de regel zoals hierboven technisch gezien de transformatie definieert tussen de nonterminal en de groep van nonterminal en terminal aan de rechterkant, kan hij de productieregel worden genoemd.
Type grammatica's
Er zijn twee soorten grammatica's, namelijk de reguliere grammatica en de contextvrije grammatica. Reguliere grammatica's worden gebruikt om een gemeenschappelijke taal te definiëren. Er is ook een recenter type grammatica bekend als Parsing Expression Grammar (PEG), die contextvrije talen representeert en ook krachtig is als contextvrije grammatica's. Hoe dan ook hangt het verschil tussen de twee types af van de notatie en hoe de regels worden geïmplementeerd.
Een eenvoudigere manier om onderscheid te maken tussen twee grammatica's zijn de _uitdrukkingen_, of de rechterkant van de regel zou in de vorm van :
In werkelijkheid is dit gemakkelijker gezegd dan gedaan, omdat een bepaald hulpmiddel meer terminal-symbolen in één definitie kan toestaan. Dan zou het de uitdrukking kunnen transformeren in een correcte reeks uitdrukkingen die tot een van de bovenstaande gevallen behoort.
Dus zelfs een vulgaire uitdrukking die je schrijft zal worden omgezet in de juiste vorm, hoewel het niet compatibel is met een natuurlijke taal.

Aangezien de parser verantwoordelijk is voor het analyseren van een reeks symbolen in een programmeertaal die voldoet aan de grammaticaregels die we zojuist hebben besproken, kunnen we de functionaliteit van de parser opsplitsen in een proces van twee stappen. Meestal krijgt de parser de opdracht om de ongestructureerde gegevens programmatisch te lezen, te analyseren en te transformeren naar een gestructureerd formaat.
De twee belangrijkste onderdelen van een parser zijn lexicale analyse en syntactische analyse. Daarnaast implementeren sommige parsers ook een semantische analysecomponent die de gestructureerde gegevens neemt en ze filtert als: positief of negatief, volledig of onvolledig. Hoewel je zou kunnen veronderstellen dat dit proces het gegevensanalyseproces verder verbetert, is dit niet altijd het geval.
Semantische analyse is niet ingebouwd in de meeste parsers vanwege de voorkeur voor menselijke semantische analyse. Daarom moet de semantische analyse een extra stap zijn en als je van plan bent om het uit te voeren, moet het een aanvulling zijn op je bedrijfsdoelen.
Laten we dan de twee hoofdprocessen van de parser bespreken.
Het wordt uitgevoerd door de Lexar, die ook wel de scanners of tokenizers worden genoemd, en hun rol is het omzetten van een reeks ruwe ongestructureerde gegevens of tekens in tokens. Vaak is deze tekenreeks die de parser binnenkomt in HTML-formaat. Vervolgens creëert de parser tokens door gebruik te maken van lexicale eenheden, waaronder sleutelwoorden, identifiers en scheidingstekens. Tegelijkertijd negeert de parser de lexicaal irrelevante gegevens die we in het inleidende gedeelte hebben aangestipt. Ze omvatten bijvoorbeeld witregels en commentaar in een HTML-document.
Nadat de parser de irrelevante tokens tijdens het lexicale proces heeft verwijderd, houdt de rest van het parseerproces zich bezig met syntactische analyse.
Deze fase van het parsen van gegevens bestaat uit het construeren van een parse tree. Dit houdt in dat de parser, nadat hij de tokens heeft gecreëerd, ze in een boom rangschikt. Tijdens dit proces worden de irrelevante tokens ook opgenomen in de nestingstructuur van de boom zelf. Onder irrelevante tokens vallen haakjes, puntkomma's en accolades.
Om je dit beter te laten begrijpen, laten we het illustreren met een eenvoudige wiskundige vergelijking: (a*2)+4
( => Parenthese
a => Waarde
* => Vermenigvuldigen
2 => Waarde
)=> Parenthese
+ => Plus
4 => Waarde
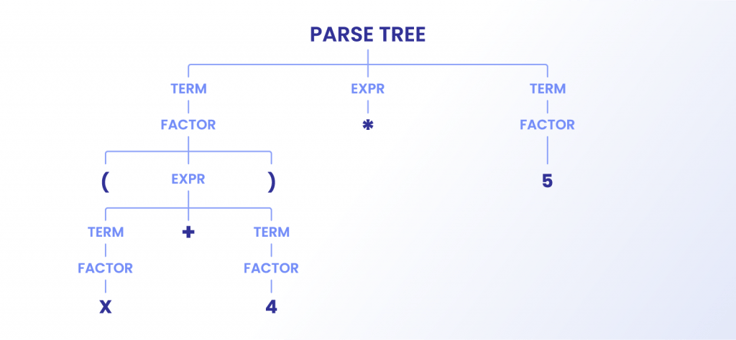
Wanneer de parser gegevens uit HTML-elementen haalt, volgt hij hetzelfde principe.
Nu heb je inzicht gekregen in de fundamentele aspecten van een parser. Nu is het tijd voor het spannende aspect of je je eigen parser moet bouwen of er een moet uitbesteden. Laten we eerst eens kijken naar de voor- en nadelen van elke methode.

Er zijn talloze voordelen als je een in-house parser bouwt. Een van de belangrijkste voordelen is dat je meer controle hebt over de specificaties. Omdat de parsers niet beperkt zijn tot één gegevensindeling, heb je bovendien de luxe om ze aan te passen aan verschillende gegevensindelingen.
Enkele andere belangrijke voordelen zijn kostenbesparingen en controle over het bijwerken en onderhouden van de ingebouwde parser.
De in-house parser is niet zonder valkuilen. Een van de grote nadelen is dat het veel van je kostbare tijd kost, terwijl je zelf de controle hebt over het onderhoud, de updates en het testen. Het andere nadeel is of je een krachtige server kunt kopen en bouwen om al je gegevens sneller te ontleden dan je nodig hebt. Tot slot zou je al je interne personeel moeten trainen om de parser te bouwen en er training over te geven.
Als je een parser uitbesteedt, bespaar je geld dat je uitgeeft aan personeel, omdat het inkopende bedrijf je alle taken geeft, inclusief servers en de parser. Bovendien is de kans kleiner dat u te maken krijgt met significante fouten, omdat het bedrijf dat de parser heeft gebouwd waarschijnlijk alle scenario's zal testen voordat ze het op de markt brengen.
Als er een fout optreedt, is er technische ondersteuning van het bedrijf waar je de parser hebt gekocht. Je zult ook veel tijd besparen omdat de besluitvorming over het bouwen van de beste parser zal worden uitbesteed.
Hoewel outsourcing veel voordelen heeft, zijn er ook nadelen. De belangrijkste nadelen komen in de vorm van aanpasbaarheid en kosten. Omdat het parsingbedrijf de volledige functionaliteit heeft gemaakt, zijn de kosten hoger. Bovendien is je volledige controle over de functionaliteit van de parser beperkt.
In dit lange artikel heb je geleerd hoe de parser werkt en hoe het data parsing proces in het algemeen werkt. Data parsing is een lang en ingewikkeld proces. Als je de kans krijgt om data parsing in de praktijk te ervaren, ben je nu goed uitgerust met een schat aan kennis om het effectief uit te voeren.
We hopen dat je deze kennis effectief zult gebruiken.