
Web scraping kan worden gedefinieerd als de methode om gegevens van websites te verzamelen en te herstructureren. Het kan ook worden gedefinieerd als de programmatische aanpak van het verkrijgen van websitegegevens op een geautomatiseerde manier. Je wilt bijvoorbeeld de e-mailadressen extraheren van alle mensen die commentaar hebben gegeven op een Facebook-post. Je kunt dit op twee manieren doen. Ten eerste kun je de cursor op de e-mailadresreeks van een willekeurige persoon richten. Je kunt het dan kopiëren en in een bestand plakken. Deze methode staat bekend als handmatig schrapen. Maar wat als je 2000 e-mailadressen wilt verzamelen? Met behulp van een web scraping tool kun je alle e-mail ID's verzamelen in 30 seconden in plaats van 3 uur als je handmatig scrapen gebruikt.
Je kunt tools voor web scraping gebruiken om informatie van websites te halen. Je hoeft alleen maar te weten hoe je moet klikken en er is geen programmeerkennis voor nodig. Deze tools zijn hulpbronefficiënt en besparen tijd en kosten. U kunt miljoenen pagina's scrapen op basis van uw behoeften zonder dat u zich zorgen hoeft te maken over de bandbreedte van het netwerk. Sommige websites implementeren anti-bots die scrapers ontmoedigen om gegevens te verzamelen. Maar goede tools voor web scraping hebben ingebouwde functies om deze tools te omzeilen en een naadloze scraping-ervaring te leveren.
Python heeft uitstekende hulpmiddelen om gegevens van het web te schrapen. Je kunt bijvoorbeeld de requests bibliotheek importeren om inhoud van een webpagina te halen en bs4(BeautifulSoup) om de relevante informatie eruit te halen. Je kunt de onderstaande stappen volgen om te webscrapen in Python. We gaan informatie van deze website halen.

Je moet de requests library importeren om de HTML van de website op te halen.
importverzoekenJe moet een GET-verzoek doen aan de website. Je kunt dit doen door de URL in de functie requests.get() te plakken.
r = requests.get('http://www.cleveland.com/metro/index.ssf/2017/12/case_western_reserve_university_president_barbara_snyders_base_salary_and_bonus_pay_tops_among_private_colleges_in_ohio.html')Extraheer de inhoud van de website met r.content. Het geeft de inhoud van de website in bytes.
c = r.inhoudJe moet de BeautifulSoup-bibliotheek importeren, omdat je hiermee eenvoudig informatie van webpagina's kunt scrapen.
van bs4 importeer BeautifulSoupJe moet een BeautifulSoup object maken van de inhoud en deze parseren met behulp van verschillende methoden.
soep = mooie soep(c)
print(soup.get_text())Je krijgt de uitvoer (het is maar een deel) ongeveer zo.
We moeten de juiste CSS-selectors vinden om de gewenste gegevens te extraheren. We kunnen de hoofdinhoud op de webpagina vinden met de .find() methode van het soepobject.
main_content = soup.find('div', attrs = {'class': 'entry-content'})We kunnen de informatie als tekst uit de tabel ophalen met behulp van het.text attribuut van de soep.
inhoud = main_content.find('ul').text
afdrukken(inhoud)
We hebben de tekst van de tabel als een string opgehaald. Maar de informatie zal van groot nut zijn als we de specifieke delen van de tekststring extraheren. Om deze taak uit te voeren, moeten we Reguliere Expressies gebruiken.
Reguliere expressies(RegEx) zijn een opeenvolging van patronen die een zoekpatroon definiëren. Het basisidee is dat:
Stel dat we de volgende informatie uit de teksttabel willen halen.

Je kunt de drie stukjes informatie extraheren door de onderstaande stappen te volgen.
Importeer re en om de salarissen te extraheren, moet je een salarispatroon maken. Gebruik de methode re.compile() om een patroon voor reguliere expressie dat als een tekenreeks wordt geleverd, te compileren tot een RegEx-patroonobject. Verder kun je pattern.findall() gebruiken om alle overeenkomsten te vinden en deze te retourneren als een lijst met strings. Elke tekenreeks vertegenwoordigt één overeenkomst.
importeer re
salaris_patroon = re.compile(r'\$.+')
salarissen = salaris_patroon.findall(inhoud)Herhaal dezelfde procedure voor het extraheren van de namen van de colleges. Maak een patroon en extraheer de namen.
school_pattern = re.compile(r'(?:,|,\s)([A-Z]{1}.*?)(?:\s\(|:|,)')
schools = school_pattern.findall(content)
print(schools)
print(salaries)
Herhaal dezelfde procedure voor het extraheren van de namen van de presidenten. Maak een patroon en extraheer de gewenste namen.
name_pattern = re.compile(r'^([A-Z]{1}.+?)(?:,)', flags = re.M)
names = name_pattern.findall(content)
print(names)
De salarissen zien er rommelig uit en zijn niet begrijpelijk. Dus gebruiken we lijstbegrip in Python om de tekenreekssalarissen om te zetten in getallen. We zullen string slicing, splitsen en join en list comprehension gebruiken om de gewenste resultaten te bereiken.
salarissen = ['$876.001', '$543.903', '$2453.896']
[int(''.join(s[1:].split(',')) voor s in salarissen]De uitvoer is als volgt:
Datavisualisatie helpt je om gegevens visueel te begrijpen zodat trends, patronen en correlaties zichtbaar worden. Je kunt een grote hoeveelheid gegevens vertalen naar grafieken, diagrammen en andere visuals om de uitschieters te identificeren en waardevolle inzichten te verkrijgen.

We kunnen matplotlib gebruiken om de gegevens te visualiseren, zoals hieronder weergegeven.
Importeer de benodigde bibliotheken zoals hieronder weergegeven.
importeer pandas als pd
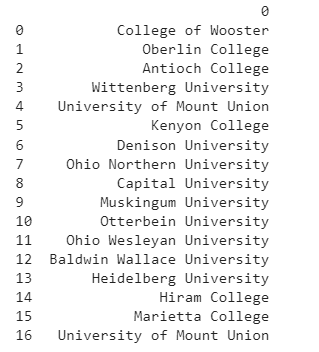
importeer matplotlib.pyplot als pltMaak een pandas dataframe van scholen, namen en salarissen. Je kunt bijvoorbeeld de scholen omzetten in een dataframe als:
df_school = pd.DataFrame(schools)
afdrukken(df_school)De uitvoer is:
Je kunt hetzelfde doen voor salarissen en namen.
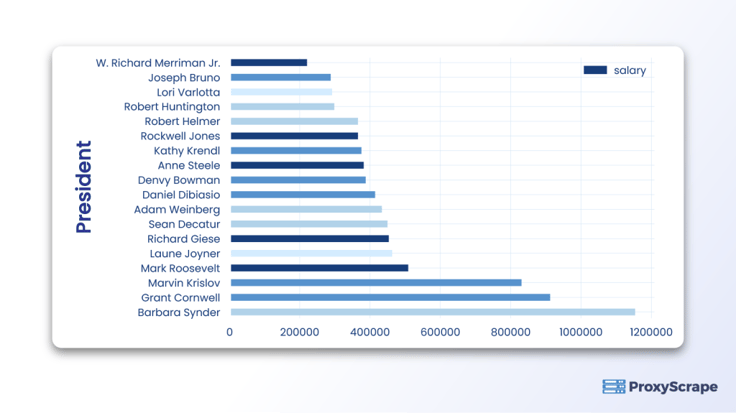
Voor de visualisatie van gegevens kunnen we een staafdiagram tekenen zoals hieronder wordt weergegeven.
df.plot(kind='barh', x = 'Voorzitter', y = 'salaris')De uitvoer is als volgt:
Web scraping helpt bedrijven om nuttige informatie over marktinzichten en industrieën te extraheren om datagestuurde diensten aan te bieden en datagestuurde beslissingen te nemen. Proxies is om de volgende redenen essentieel om effectief gegevens van verschillende websites te scrapen.

Weet je hoeveel proxies nodig zijn om de bovenstaande voordelen te krijgen? Je kunt het benodigde aantal proxies berekenen met deze formule:
Aantal proxies = aantal toegangsverzoeken / crawlsnelheid
Het aantal toegangsverzoeken hangt af van de volgende parameters.
Aan de andere kant wordt de crawlsnelheid beperkt door het aantal verzoeken dat de gebruiker in een bepaalde tijd doet. Sommige websites staan een beperkt aantal aanvragen per gebruiker toe om onderscheid te maken tussen geautomatiseerde en menselijke gebruikersaanvragen.

Je kunt proxies in Python gebruiken door de onderstaande stappen te volgen.
importverzoekenproxy = 'http://114.121.248.251:8080'
url = 'https://ipecho.net/plain'page = requests.get(url,
proxies={"http": proxy, "https": proxy})afdrukken(pagina.tekst)De uitvoer is als volgt:
We hebben besproken dat we web scraping kunnen gebruiken om gegevens van websites te halen in plaats van handmatig te schrapen. Web scraping is kostenefficiënt en een tijdbesparend proces. Bedrijven gebruiken het om webinformatie te verzamelen en te herstructureren om datagestuurde beslissingen te nemen en waardevolle inzichten te verkrijgen. Het gebruik van proxies is essentieel voor veilig webschrapen omdat het het originele IP-adres van de gebruiker verbergt van de doelwebsite. U kunt een datacenter of residentiële proxies gebruiken voor web scraping. Maar gebruik liever residentiële proxies omdat ze snel zijn en niet gemakkelijk kunnen worden gedetecteerd. Verder kunnen we reguliere expressies in Python gebruiken om sets van tekenreeksen te matchen of te vinden. Dit betekent dat we een willekeurig tekenreekspatroon uit de tekst kunnen halen met behulp van reguliere expressies. We hebben ook gezien dat datavisualisatie grote hoeveelheden gegevens omzet in grafieken, diagrammen en andere visuals die ons helpen om afwijkingen te detecteren en nuttige trends in de gegevens te identificeren.