
Web scraping is de kunst om gegevens van het internet te halen en ze te gebruiken voor zinvolle doeleinden. Het staat ook bekend als web data extraction of web data harvesting. Voor nieuwelingen is het gewoon hetzelfde als gegevens kopiëren van het internet en ze lokaal opslaan. Het is echter een handmatig proces. Web scraping is een geautomatiseerd proces dat werkt met behulp van web crawlers. Webcrawlers maken verbinding met het internet via het HTTP-protocol en stellen de gebruiker in staat om op een geautomatiseerde manier gegevens op te halen. Men kan het internet beschouwen als verrijkte grond en gegevens als de nieuwe olie, terwijl web scraping de techniek is om die olie te extraheren.
De mogelijkheid om gegevens van het internet te schrapen en te analyseren is een essentiële techniek geworden, of je nu een datawetenschapper, ingenieur of marketeer bent. Er kunnen verschillende gebruikssituaties zijn waarbij het schrapen van webgegevens enorm kan helpen. In dit artikel zullen we gegevens van Amazon scrapen met Python. Tot slot zullen we ook de geschraapte gegevens analyseren en zien hoe belangrijk dit is voor een normaal persoon, datawetenschapper of persoon die een e-commercewinkel runt.
Gewoon een kleine voorzorgsmaatregel: Als Python en web scraping nieuw voor je zijn, is dit artikel misschien wat moeilijker te begrijpen. Ik zou aanraden om de inleidende artikelen op ProxyScrape en dan naar dit artikel gaan.
Laten we beginnen met de code.
Allereerst importeren we alle bibliotheken die nodig zijn voor de code. Deze bibliotheken worden gebruikt voor het schrapen en visualiseren van gegevens. Als je de details van elk van deze bibliotheken wilt weten, kun je terecht in hun officiële documentatie.
importeer pandas als pd
importeer numpy als np
importeer matplotlib.pyplot als plt
importeer seaborn als sns
%matplotlib inline
importeer re
importeer tijd
uit datetime importeer datetime
importeer matplotlib.dates als mdates
importeer matplotlib.ticker als ticker
uit urllib.request importeert urlopen
van bs4 importeert BeautifulSoup
importeer verzoekenNu gaan we de nuttige informatie van de best verkochte boeken van Amazon scrapen. De URL die we gaan scrapen is:
https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_’+str(pageNo)+’?ie=UTF8&pg=’+str(pageNo)
Omdat we toegang moeten krijgen tot alle pagina's, lopen we door elke pagina om de benodigde dataset te krijgen.
Om verbinding te maken met de URL en de HTML-inhoud op te halen, is het volgende vereist,
Enkele van de belangrijke tags waaronder onze belangrijke gegevens zich zullen bevinden zijn,
Als je de gegeven pagina inspecteert, zie je de parent tag en de bijbehorende elementen.
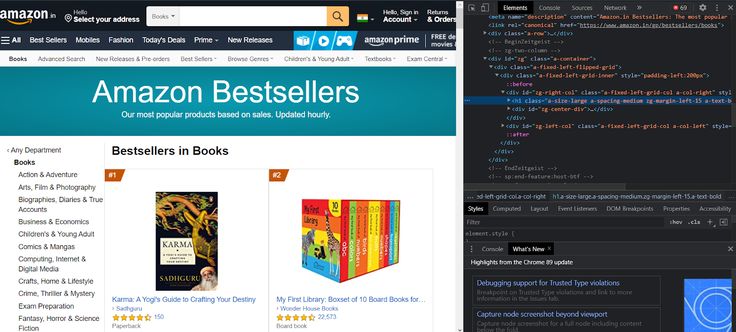
Als je een bepaald kenmerk wilt inspecteren, ga je naar elk kenmerk en inspecteer je het. Je vindt een aantal belangrijke kenmerken voor de auteur, de naam van het boek, de waardering, de prijs en de klanten die het boek beoordelen.
In onze code gebruiken we geneste if-else-statements om extra bevindingen toe te passen voor auteurs die niet geregistreerd zijn bij Amazon.
no_pages = 2
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
#print(soup)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-none aok-relative'}):
#print(d)
name = d.find('span', attrs={'class':'zg-text-center-align'})
n = name.find_all('img', alt=True)
#print(n[0]['alt'])
author = d.find('a', attrs={'class':'a-size-small a-link-child'})
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('a', attrs={'class':'a-size-small a-link-normal'})
price = d.find('span', attrs={'class':'p13n-sc-price'})
all1=[]
if name is not None:
#print(n[0]['alt'])
all1.append(n[0]['alt'])
else:
all1.append("unknown-product")
if author is not None:
#print(author.text)
all1.append(author.text)
elif author is None:
author = d.find('span', attrs={'class':'a-size-small a-color-base'})
if author is not None:
all1.append(author.text)
else:
all1.append('0')
if rating is not None:
#print(rating.text)
all1.append(rating.text)
else:
all1.append('-1')
if users_rated is not None:
#print(price.text)
all1.append(users_rated.text)
else:
all1.append('0')
if price is not None:
#print(price.text)
all1.append(price.text)
else:
all1.append('0')
alls.append(all1)
return allsDit voert de volgende functies uit,
voor i in bereik(1, geen_pagina's+1):
results.append(get_data(i))
plat = lambda l: [item voor sublijst in l voor item in sublijst]
df = pd.DataFrame(flatten(results),columns=['Book Name','Author','Rating','Customers_Rated', 'Price'])
df.to_csv('amazon_products.csv', index=False, encoding='utf-8')We gaan nu het csv-bestand laden,
df = pd.read_csv("amazon_products.csv")
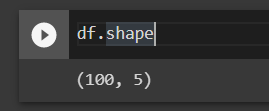
df.vormDe vorm van het dataframe laat zien dat er 100 rijen en 5 kolommen in het CSV-bestand staan.
Laten we de 5 rijen van de dataset bekijken,
df.head(61)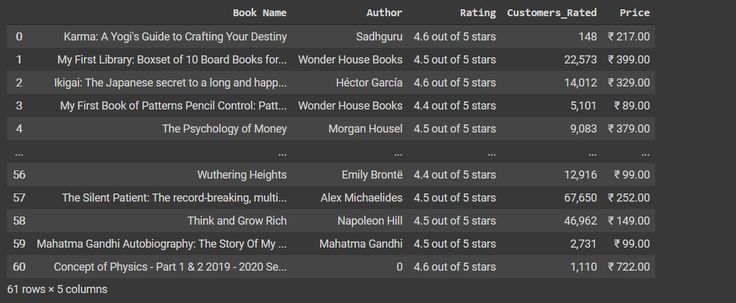
We gaan nu wat voorbewerkingen uitvoeren op de ratings, customers_rated en price kolom.
df['Rating'] = df['Rating'].apply(lambda x: x.split()[0])
df['Rating'] = pd.to_numeric(df['Rating'])
df["Prijs"] = df["Prijs"].str.replace('₹', '')
df["Prijs"] = df["Prijs"].str.replace(',', '')
df['Prijs'] = df['Prijs'].apply(lambda x: x.split('.')[0])
df['Prijs'] = df['Prijs'].astype(int)
df["Klanten_Gerateerd"] = df["Klanten_Gerateerd"].str.replace(',', '')
df['Customers_Rated'] = pd.to_numeric(df['Customers_Rated'], errors='ignore')
df.head()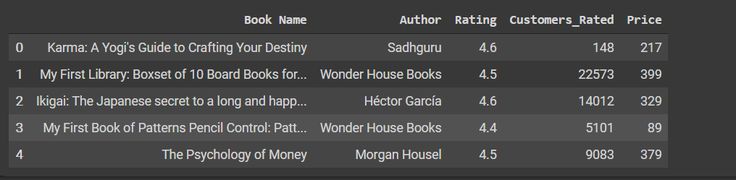
Als we kijken naar de typen dataframes, krijgen we,
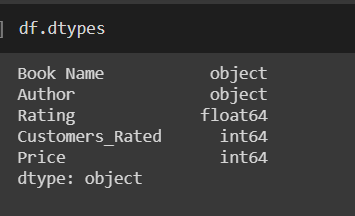
Er is wat onvolledige informatie in de uitvoer hierboven. We zullen eerst het aantal NaN's tellen en ze dan weglaten.
df.replace(str(0), np.nan, inplace=True)
df.replace(0, np.nan, inplace=True)
count_nan = len(df) - df.count()
telling_nan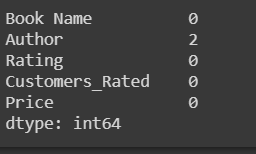
df = df.dropna()We zullen nu alle auteurs met het duurste boek leren kennen. We maken kennis met de top 20 van hen.
data = data.sort_values(['Rating'],axis=0, ascending=False)[:15]
gegevens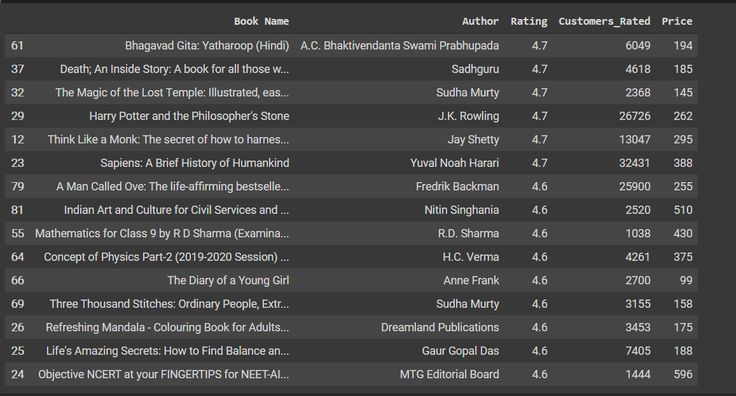
We zien nu de best beoordeelde boeken en auteurs met betrekking tot de klantwaardering. We filteren de auteurs en boeken met minder dan 1000 beoordelingen, zodat we de beroemdste auteurs te zien krijgen.
data = df[df['Klanten_beoordeling'] > 1000]
data = data.sort_values(['Rating'],axis=0, ascending=False)[:15]
gegevens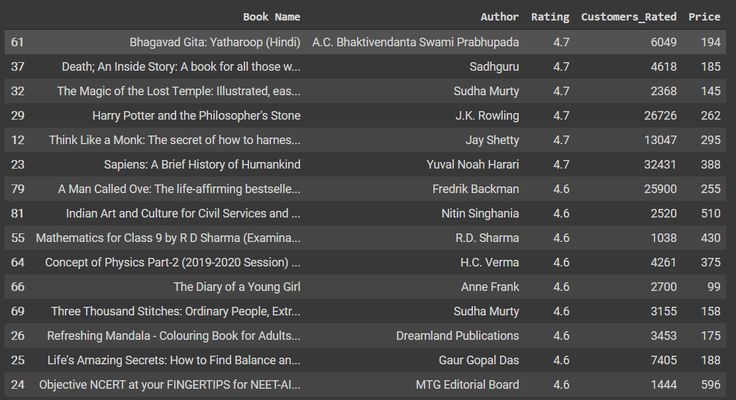
Laten we eens kijken naar de best beoordeelde boeken,
p = figuur(x_range=data.iloc[:,0], plot_width=800, plot_height=600, title="Best beoordeelde boeken met meer dan 1000 klanten", toolbar_location=None, tools="")
p.vbar(x=data.iloc[:,0], top=data.iloc[:,2], width=0.9)
p.xgrid.grid_line_color = Geen
p.y_range.start = 0
p.xaxis.major_label_orientation = math.pi/2
weergeven(p)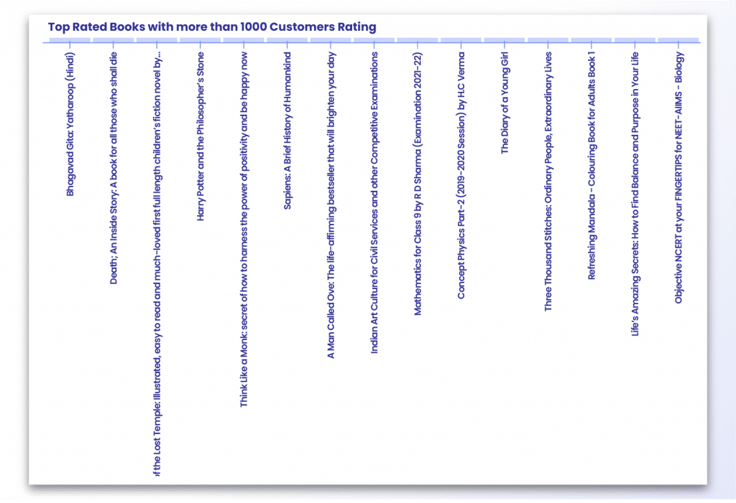
Hoe meer beoordelingen, hoe groter het vertrouwen van de klant. Het zal dus overtuigender en geloofwaardiger zijn als we de auteurs en boeken toevoegen die het meest worden gewaardeerd door de klanten.
uit bokeh.transform importeer factor_cmap
uit bokeh.models importeer Legend
uit bokeh.palettes importeer Dark2_5 als palette
importeer itertools
uit bokeh.palettes importeer d3
#colors heeft een lijst met kleuren die gebruikt kunnen worden in plots
kleuren = itertools.cycle(palette)
palette = d3['Category20'][20]
index_cmap = factor_cmap('Auteur', palette=palette,
factoren=data["Auteur"])
p = figure(plot_width=700, plot_height=700, title = "Top Authors: Waardering vs. Klanten gewaardeerd")
p.scatter('Rating','Customers_Rated',source=data,fill_alpha=0.6, fill_color=index_cmap,size=20, legend='Author')
p.xaxis.axis_label = 'Waardering'.
p.yaxis.axis_label = 'KLANTEN WAARDERING'.
p.legend.location = 'top_left'.
toon(p)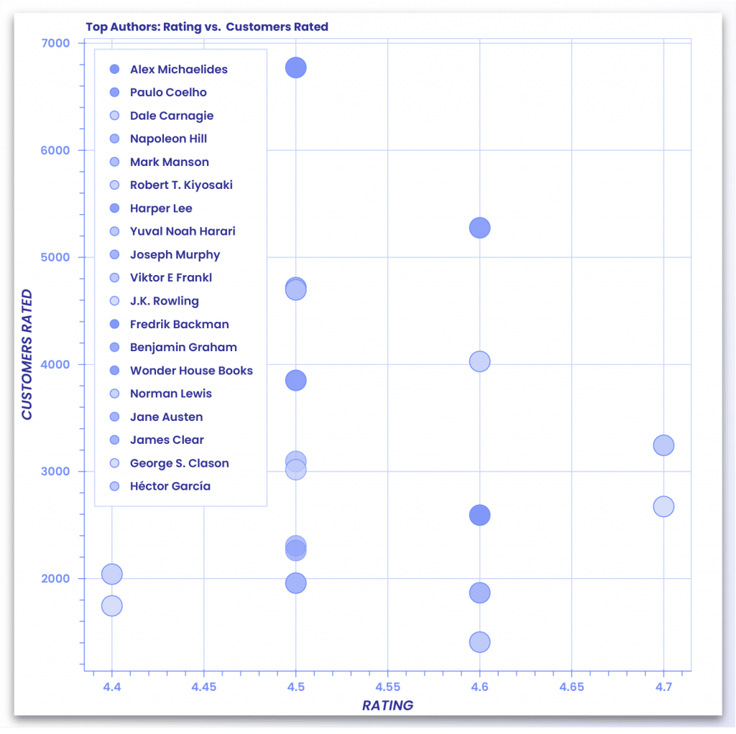
In dit artikel hebben we gezien wat web scraping is door een zeer belangrijke use case te nemen, namelijk het extraheren van gegevens van Amazon. We hebben niet alleen gegevens van verschillende Amazon-pagina's gehaald, maar we hebben de gegevens ook gevisualiseerd met behulp van verschillende Python-bibliotheken. Dit artikel was voor gevorderden en is misschien moeilijk te begrijpen voor mensen die nieuw zijn op het gebied van web scraping en datavisualisatie. Voor hen raad ik aan om naar de startersartikelen te gaan die beschikbaar zijn op ProxyScrape. Web scraping is een zeer nuttige techniek die je bedrijf een boost kan geven. Er zijn ook enkele fantastische betaalde tools beschikbaar op de markt, maar waarom zou je die betalen als je je eigen scraper kunt coderen. De code die we hierboven hebben geschreven, werkt misschien niet voor elke webpagina omdat de paginastructuur kan verschillen. Maar als je de bovenstaande concepten hebt begrepen, dan zijn er geen obstakels voor je om elke webpagina te scrapen door de code aan te passen aan de structuur. Ik hoop dat dit artikel interessant was voor de lezers. Dat was alles. Tot de volgende!