
Organisaties extraheren momenteel enorme hoeveelheden gegevens voor analyse, verwerking en geavanceerde analyse om patronen te identificeren uit deze gegevens, zodat belanghebbenden weloverwogen conclusies kunnen trekken. Omdat Data Science snel groeit en in veel sectoren een revolutie teweeg heeft gebracht, is het de moeite waard om te weten hoe organisaties deze enorme hoeveelheden gegevens extraheren.
Tot nu toe heeft de datawetenschap het web gebruikt om grote hoeveelheden gegevens te schrapen voor hun behoeften. Daarom richten we ons in dit artikel op web scraping voor data science.
Web scraping, ook bekend als web harvesting of screen scraping, of web data extractie, is de manier om grote hoeveelheden gegevens van het web te halen. In Data Science hangt de nauwkeurigheid van de standaard af van de hoeveelheid gegevens die je hebt. De dataset is vooral belangrijk voor het trainingsmodel omdat je verschillende aspecten van de gegevens test.
Ongeacht de omvang van je bedrijf zijn gegevens over je markt en analyses essentieel voor je bedrijf om je concurrenten voor te blijven. Elke kleine beslissing om je bedrijf te verbeteren wordt gedreven door gegevens.
Nadat je gegevens van verschillende bronnen op het web hebt gehaald, kun je ze onmiddellijk analyseren, ook wel realtime analyse genoemd. Er zijn echter gevallen waarin een vertraagde analyse geen zin heeft. Een typisch voorbeeld van een situatie die real-time analyse vereist, is de analyse van aandelenkoersgegevens en CRM (Customer Relationship Management).

Het web bevat een overvloed aan gegevens over elk willekeurig onderwerp, variërend van complexe gegevens over de lancering van een ruimtemissie tot persoonlijke gegevens zoals je post op Instagram over wat je bijvoorbeeld hebt gegeten. Al deze ruwe gegevens zijn van enorme waarde voor datawetenschappers die de gegevens kunnen analyseren en er conclusies uit kunnen trekken door er waardevolle inzichten uit te halen.
Er zijn een handvol open-source gegevens en websites die gespecialiseerde gegevens leveren die datawetenschappers nodig hebben. Gewoonlijk kunnen mensen dergelijke sites één keer bezoeken om gegevens handmatig te extraheren, wat tijdrovend zou zijn. Als alternatief kun je de gegevens ook opvragen, waarna de server de gegevens ophaalt.
De gegevens die je nodig hebt voor data science of machine learning zijn echter behoorlijk omvangrijk, en een enkele website is redelijkerwijs niet voldoende om aan dergelijke behoeften te voldoen. Dit is waar je je moet wenden tot web scraping, je ultieme redder.
Data Science omvat het uitvoeren van geavanceerde taken zoals NLP (Natural Language Processing), beeldherkenning, enz., samen met AI (Artificial Intelligence), die van enorm nut zijn voor onze dagelijkse behoeften. In dergelijke omstandigheden is web scraping het meest gebruikte hulpmiddel dat automatisch gegevens van het web downloadt, parseert en organiseert.
In dit artikel zullen we ons richten op verschillende web scraping scenario's voor data science.
Het is van vitaal belang om bij de website die je van plan bent te scrapen na te gaan of deze scraping door externe entiteiten toestaat. Hier zijn dus specifieke stappen die je moet volgen voordat je gaat scrapen:
Robot.txt-bestand - Umoet het robot.txt-bestand controleren op hoe u of uw bot met de website moet omgaan, omdat het een reeks regels hiervoor bevat. Met andere woorden, het bepaalt welke pagina's van een website u wel en niet mag openen.
Je kunt er gemakkelijk naartoe navigeren door website_url/robot.txt in te typen, omdat deze zich in de hoofdmap van een website bevindt.
Gebruiksvoorwaarden-Maakzeker dat je de gebruiksvoorwaarden van de doelwebsite bekijkt. Als er bijvoorbeeld in de gebruiksvoorwaarden staat dat de website de toegang voor bots en spiders niet beperkt en snelle verzoeken aan de server niet verbiedt, zou je kunnen scrapen.
Copyrights - Nahet extraheren van gegevens moet je voorzichtig zijn met waar je ze wilt gebruiken. Je moet er namelijk voor zorgen dat je geen auteursrechten schendt. Als de gebruiksvoorwaarden geen beperking bevatten voor een bepaald gebruik van gegevens, dan kun je zonder schade scrapen.
De meeste web scraping projecten hebben real-time gegevensanalyse nodig. Real-time gegevens zijn gegevens die je kunt presenteren op het moment dat ze worden verzameld. Met andere woorden, dit soort gegevens wordt niet opgeslagen maar direct doorgegeven aan de eindgebruiker.
Real-time analytics is iets heel anders dan batch-stijl analytics, omdat de laatste uren of aanzienlijke vertragingen nodig heeft om gegevens te verwerken en waardevolle inzichten te produceren.
Enkele voorbeelden van realtime gegevens zijn e-commerce aankopen, weersomstandigheden, logbestanden, geolocaties van mensen of plaatsen en serveractiviteit, om maar een paar voorbeelden te noemen.
Laten we eens kijken naar een aantal use cases van real-time analytics:
Dus nu is de vraag: hoe schraap je realtime gegevens voor analyse?
Aangezien alle bovenstaande use cases aangeven dat realtime analyse afhankelijk is van het verwerken van grote hoeveelheden gegevens, is dit waar web scraping om de hoek komt kijken. Real-time analyse kan niet plaatsvinden als de gegevens niet onmiddellijk worden opgevraagd, geanalyseerd en geëxtraheerd.
Daarom wordt een scraper met een lage latentie gebruikt om snel gegevens van doelwebsites te scrapen. Deze scrapers scrapen gegevens door deze met een zeer hoge frequentie te extraheren, gelijk aan de snelheid van de website. Hierdoor leveren ze ten minste bijna realtime gegevens voor analyses.
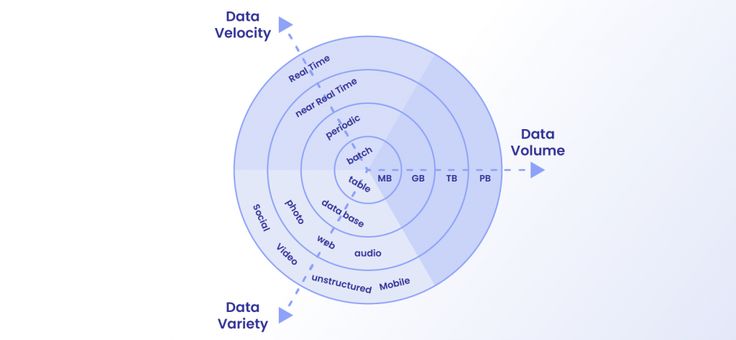
Bij Natural Language Processing (NLP) worden gegevens over natuurlijke talen zoals Engels in tegenstelling tot programmeertalen zoals Python aan computers geleverd zodat ze deze kunnen begrijpen en verwerken. Natural Language Processing is een breed en ingewikkeld vakgebied omdat het niet eenvoudig is om te achterhalen wat bepaalde woorden of zinnen betekenen.

Een van de meest voorkomende toepassingen van NLP is dat datawetenschappers commentaren van klanten op sociale media over een bepaald merk gebruiken om te verwerken en te beoordelen hoe een specifiek merk presteert.
Aangezien het web dynamische bronnen zoals blogs, persberichten, forums en klantbeoordelingen bevat, kunnen deze worden geëxtraheerd om een enorme tekstcorpora van gegevens voor Natural Language Processing te vormen.

Bij voorspellend modelleren gaat het om het analyseren van gegevens en het gebruiken van waarschijnlijkheidstheorie om de voorspellende uitkomsten voor toekomstige scenario's te berekenen. Voorspellende analyse gaat echter niet over een precieze voorspelling van de toekomst. In plaats daarvan gaat het om het voorspellen van de waarschijnlijkheid dat het zal gebeuren.
Elk model heeft voorspellende variabelen die toekomstige resultaten kunnen beïnvloeden. Je kunt de gegevens die je nodig hebt voor vitale voorspellingen van websites halen door middel van web scraping.
Enkele toepassingen van voorspellende analyse zijn:
Het succes van voorspellende analyses hangt grotendeels af van de aanwezigheid van grote hoeveelheden bestaande gegevens. U kunt een analyse formuleren zodra u de gegevensverwerking hebt voltooid.
Machine Learning is het concept waarmee machines zelf kunnen leren nadat je ze hebt gevoed met trainingsgegevens. Natuurlijk verschillen de trainingsgegevens per specifieke toepassing. Maar je kunt opnieuw het web gebruiken om trainingsgegevens te verzamelen voor verschillende machine-leermodellen met verschillende gebruikssituaties. Als je dan trainingsdatasets hebt, kun je ze leren om gecorreleerde taken uit te voeren, zoals clustering, classificatie en attributie.
Het is van het grootste belang om gegevens te scrapen van kwalitatief hoogwaardige webbronnen, omdat de prestaties van het model voor machinaal leren afhangen van de kwaliteit van de trainingsdataset.
Het doel van een proxy is om je IP-adres te maskeren wanneer je van een doelwebsite schraapt. Aangezien je van meerdere webbronnen moet scrapen, is het ideaal om een proxy pool te gebruiken die rouleert. Het is ook zeer waarschijnlijk dat dergelijke websites het maximum aantal keren opleggen dat je ze kunt verbinden.
In dat opzicht moet je IP-adressen roteren met behulp van verschillende proxies. Om meer te weten te komen over de proxies, raadpleeg je onze laatste blogartikelen.
Inmiddels heb je een redelijk idee van de soorten gegevens die je moet verzamelen voor Data Science. Datawetenschap is inderdaad een ingewikkeld vakgebied dat uitgebreide kennis en ervaring vereist. Als datawetenschapper moet je ook inzicht hebben in de verschillende manieren waarop web scraping wordt uitgevoerd.
We hopen dat dit artikel een fundamenteel inzicht heeft gegeven in scraping voor data science, en dat het van grote waarde zal zijn voor jou.